.png)
Chapter 3
SUGGESTION FORMULA
Previously, we established that the suggestion formula emerges where there are repetition, rhythm, and semantic series, and cited S. M. Eisenstein's idea that the cinematic frame is a natural stimulus for the brain.
In our model, the repetition of the same seme leads to resonance phenomena in the brain (like a frame, the seme stimulates neural centers); it is precisely these resonance phenomena that underlie our ability to enjoy works of art.
Research conducted at the Bekhterev Institute of Neurophysiology[24] showed that the same brain cell is activated when stimulated by a seme, sound, and image. If we recall that the brain communicates with the body in the language of electrical impulses, and that the activation of one nerve center changes the frequency of oscillations of electrical impulses generated by the human brain, then the assumption about resonance phenomena does not seem too improbable. Incidentally, the familiar phenomenon of “frisson” or “aesthetic chills”, which we experience when perceiving a remarkable work of art, also points to resonance.
In Chapter 2, we tried to show how semantic series form the suggestion formula. As for the sonic aspect of verse, it is known that vowel sounds are carriers of emotions. If the seme of the suggestion formula is the seme of emotion (and this is almost always the case in verse), then vowels and consonants could well work toward the suggestion formula, as can meter, which is used in sound writing. Note that sound and meter can still play only a secondary role in poetry. This is proven by the existence of literary parody, where sometimes both meter and sound structure of the original are preserved (for example, in Yu. Levitansky's parodies), but the parodist destroys the suggestion formula of the original.
It was probably for the same reason that the Futurists failed to achieve their goal. Remember Alexey Kruchenykh, whose poems today are rarely referred to without irony as zaum[25], trans-rational poetry. This dismissive view misses his intent – Kruchenykh was deliberately attempting to create zaum, poetry that would transcend rational meaning. Through sonorous combinations, he attempted to bypass reason and speak directly to the emotional centers of the subconscious, which remain beyond rational control. However, what is achievable in music seems beyond poetry's reach today (we emphasize today, as this limitation seems to be relevant to our time). There are grounds to believe that this was not always so. We will return to this discussion in Chapter 7, where we consider how different art forms employ different means while sharing a common goal: the creation of a suggestion formula.[26]
Let's assume that the emotions carried by meter, stressed vowel sounds, and semantic repetition enter into symmetrical relationships. Does this affect the suggestion formula? Consider two different translations of the same poem, each using different meter and different words while conveying the same content. Take, for instance, Tyutchev's (1826)[27] and Lermontov's (1841)[28] translations of Heine's most famous poem “Ein Fichtenbaum steht einsam”[29] (The Pine Tree, 1822-1823) – they are of vastly different quality, where Lermontov's “На севере диком стоит одиноко” (“In the wild North a pine tree stands alone”) achieved the status of a world lyric masterpiece. Would the suggestion formula remain the same in such translations? Suppose two translators understood the meaning of the translated text in the same way. In that case, the suggestion formulas in the translations (as in the case with Lermontov and Tyutchev) will most likely coincide. But the degree of realization of the suggestion formula in the verse – surely will not.
In Chapter 2, we saw how the same suggestion formula can have different realizations (recall our quatrains constructed from words sharing the seme of loneliness). Now, we will examine what conditions lead to the most effective realization of the suggestion formula.
1. We presume that one key condition for the effective realization of the suggestion formula appears to be its concealment – the formula must remain encoded to be perceived subconsciously. Consider hypnosis: it is well known that a person consciously resisting hypnosis is difficult to hypnotize.[30] However, when there is no awareness of suggestion taking place, resistance is absent. This concealment of the suggestion formula is made possible by circumventing the rational thinking which tends to fail recognizing semantic connections between words belonging to the same semantic series. Take the example from Chapter 2. Would our mind find any logical connection between the words “loneliness”, “circle”, and “wind”? Very unlikely. Yet when combined in phrases (“lonely wind in circles”, “circles of loneliness of winds”, “circles of winds and loneliness”), they create a powerful mood precisely because they belong to the same semantic series – the series of loneliness. By contrast, direct repetition of the same words would only lead to semantic satiation, presumably because it decodes the suggestion formula, making it too obvious.
2. We know that the suggestion formula emerges where there is certain degree of repetition, symmetry, rhythm, and semantic series. For a seme to be suggested effectively, it must be repeated a certain number of times.
CONCLUSION: The effectiveness of the suggestion formula depends on the frequency with which the suggested seme appears in the text. If the seme appears too few times, the suggestion fails to take hold – the reader remains unmoved and unconvinced. This is understandable. However, if the seme appears too frequently, there is reason to believe the suggestion formula will be undermined – leaving the reader equally unmoved and unconvinced.
Marina Tsvetaeva believed that excessive repetition makes things appear ridiculous. This holds true, but only starting from a certain point. Beyond that point, what is excessively repeated loses its meaning entirely, dissolving into meaningless sounds. This can be easily demonstrated: take any word and repeat it aloud – in a matter of moments, it becomes merely an abstract collection of sounds, stripped of meaning for consciousness. Once you stop repeating it, the meaning gradually returns. This phenomenon, known to psychologists and linguists as “semantic satiation”, has been the subject of scientific study. Some researchers, notably Osgood and Hull, have approached it through stimulus-response theory. Osgood suggests that if word meaning is understood as a response to verbal stimulus, this response naturally diminishes with repeated stimulus presentation. Hull's learning theory elaborates on this, proposing that “reactive inhibition accumulates upon repeated pairings of stimulus and response, bringing about temporary inhibition of response”. Following this theoretical framework, if we view word meaning as a response either to the word's sonority or to the act of pronunciation itself, Hull's theory would predict that repeated presentation of the word would temporarily inhibit such meaning-response.[31]
We will not address here the legitimacy of how behaviorists like Osgood and Hull identify word meaning with reaction to a word. Even if, as opponents of the reactive theory argue, there is some intermediary between word and reaction – namely, the word's meaning – this does not significantly alter our understanding of semantic satiation. After all, if a phenomenon evokes no reaction in us whatsoever, it effectively does not exist for us – we cannot perceive it. The only change to Hull's scheme would be that instead of: “word → reaction → inhibition → absence of reaction” we would have: “word → meaning → reaction → inhibition → absence of reaction → absence of meaning”.
To return to the concept of resonance in connection to neurophysiological stimuli, it could be appropriate to note that in physics, resonance can lead to the destruction of resonating bodies. Might we be observing in inhibition and absence of reaction some kind of protective mechanism of the organism?
We can conclude, therefore, that a poem's maximum impact on the reader depends on achieving an optimal number of seme repetitions within one semantic series. But can we determine the boundaries of such repetition? In principle, yes – if we resolve several key problems, including those outlined below.
1. Two fundamental considerations:
a) Suggestion intensity varies with text length. The same number of seme repetitions will produce different effects in a 500-word text versus a 1000-word text.
b) Different words carry varying degrees of saturation with a given seme.
To address this, we propose introducing two terms: “text saturation with seme” and “word saturation with seme”. We can approximately assume that a word's saturation with a seme depends on how much of the area of that word's meaning field that seme occupies. Thus, determining optimal text saturation with a given seme means establishing optimal boundaries for seme repetition. While expert evaluation can measure how saturated individual words are with their constituent semes, we can measure more precisely the relative saturation of different words within a semantic series with their seme-identifier – and the method for doing so is known.
Between 1920s and 1950s, Soviet psychologists Alexander Luria and Olga Vinogradova conducted a series of experiments directly related to what we are discussing in this chapter.
The work of Luria and Vinogradova (1959) is especially interesting in that it seems to reveal levels of relatedness of meanings in semantic fields. Subjects were given electric shock upon the presentation of a given word in a series, and the generalization of vasomotor responses to other words was tested. It was found that subjects made an involuntary defense response (vasoconstriction of the blood vessels of both the finger and the forehead) to words close in meaning to the word on which they received shock, and that they made an involuntary orienting response (vasoconstriction in the finger and vasodilation in the forehead) to words more distantly related to the critical word. For example, if a subject was given a shock to the word violin, he made a similar defense reaction to such words as violinist, bow, string, mandolin, and others. He made an orienting response to names of stringless musical instruments, such as accordion and drum, and to other words connected with music, such as sonata and concert. In addition, of course, there were neutral words to which the subject made no autonomic response.
This experiment revealed not only the existence of complex semantic structures, but also that the subjects themselves were largely unconscious of such structures. While they responded consistently on an involuntary response basis, when interviewed after the experiment they were usually not aware of obvious semantic clusters of words to which they had responded.[32]
The phenomenon dеscribed in the above experiment became known as “semantic generalization”. Clearly, all words that triggered reactions belonged to the same semantic series. Nalimov, in his book “Probabilistic Models of Language”, proposed a model of Bayesian inference (or Bayesian reading) which we mentioned earlier. In simplified form, this model suggests that each person associates an a priori meaning with any given word, which surfaces in consciousness whenever they encounter that word. If this a priori meaning doesn't fit the phrase's context, the next potential meaning becomes available, and so on until a suitable one is found.
Thus, all word meanings have a probabilistic character, and for each person, one could construct a probabilistic scale (in descending order) of all possible meanings for any given word. Nalimov's actual model is more sophisticated than this description suggests, as it accounts for the continuity of the field of word meanings.
We are interested, however, in a slightly different aspect of the model. The broader the portion of a word's meaning field activated in a phrase, the closer the corresponding meaning appears to be to the maximum values on the probabilistic scale. Words in a semantic series formed by a seme with high a priori probability for the electric shock-associated word should have evoked stronger protective reactions than words in series formed by semes whose a priori probability for “shocking” word is low (corresponding to a narrow part of the meaning field).
Yet, we defined word saturation with a given seme to be directly proportional to the area occupied in the meaning field and thus to the a priori probability of that seme's realization for that word. Therefore, higher word saturation with a given seme should correlate with stronger protective reactions to words in the corresponding semantic series – exactly what the Soviet psychologists observed in their experiment.
For example, in the meaning field of “violin”, the semantic quanta combination “string musical instrument” should occupy a larger area than “musical instrument”, which in turn occupies more than “musical performance” or simply “music”.
Charles E. Osgood believes that the phenomenon of semantic generalization confirms the reactive theory of meaning. Suppose a series of different stimuli (for example, words) causes the same reaction (for instance, meaning). In that case, these stimuli are equivalent, and the reaction caused by one of these words extends to other words through internal mediated reactions, the types of which Osgood described.
Dan Slobin, criticizing supporters of reactive theories of word meaning (including Osgood), argues that studies of semantic generalization cannot explain the fact that different words have different meanings:
In the Luria and Vinogradova experiment, for example, a response conditioned to the word violin generalized to such words as bow, string, violinist, and mandolin. Following Osgood's argument, one would have to claim that these words are all synonyms.[33]
Assessment of meaning's reactive nature lies outside the scope of this work, but for objectivity's sake we must note that Slobin's remark seems peculiar. The words “bow”, “string”, “violinist”, “mandolin” do indeed share a common seme. Different words have different maximum-probability meanings, while other meanings in different words may coincide. Evidently, we traditionally designate as synonyms those words that are close precisely in their maximum-probability a priori meanings.
Thus, to create an optimal suggestion formula, a text of given length should maintain optimal saturation with a given seme regardless of its constituent words. In other words, $Y(L) = F(\sum_{}^{}{X(i)}$), where Y represents the optimal saturation with a seme of the text of length L, X represents the word’s saturation with seme, and i represents the word (image) of text.
Since text itself is a variable with length as its sole constant attribute, its constituent words must also be variables. However, Y remains constant for any given value of L. Each value of L must have its corresponding constant value Y – the optimal saturation of text of length L with given seme S.[34]
2. Another important factor that must be taken into account is the reader's emotional state, which may either coincide with or contradict the suggested emotion. In this case, the inertia of thinking can alter the value of optimal text saturation with seme for a given recipient. Thus, even for a single recipient, the optimal text saturation with seme is not constant.
3. Let us suppose we have managed to measure the optimal saturation with seme of text of length L (though along the way, we will need to resolve another complex question: what constitutes a unit of text length? Clearly, a unit of text length is not a letter, not a sound, and probably not even a word). This can be done experimentally by taking as a model some poem in which the suggestion formula is close to the optimal.
Then, if we know the saturation of each word belonging to a certain semantic series with seme S, the identifier of the semantic series, we can compose such a combination of words belonging to the semantic series whose identifier is seme S, that $\sum_{}^{}{X(i)}$ would approximate Y(L), where Y(L) represents the optimal saturation with seme S of text of length L, which we composed from words belonging to the semantic series with identifier S.
Now, however, we encounter another difficulty. Consider the word combination “table of death”. Clearly, it is saturated with the seme of death. Now let us slightly modify this:
“Table of death of a porcupine” – V1
or
“Table of death of Ivan Fedorovich” – V2
or
“Table of your death” – V3
Variant V3 evokes a stronger emotion than V2 and V1. Variant V1 evokes almost no emotion. However, the saturation with the seme of death in the phrase “table of death” consists of X(table) and X(death). The saturation with the seme of death in variant V1 consists of X(table), X(death) and X(porcupine), where X represents the saturation of the word with the seme of death. Thus, the saturation value with the seme of death for variant V1, calculated according to our formula, exceeds that of the word combination “table of death”. Yet the length of V1 does not appear to exceed the length of “table of death” sufficiently to warrant such a significant increase in the value of Y for variant V1. Moreover, it is evident that the value X(V1) is immeasurably less than the value X(table of death). We seem to have overlooked something here. Specifically, we may have failed to account for both the volume a word occupies in the text and, however slight it may seem, the difference in lengths between the two texts.
In V1 the maximum volume is occupied by the word “porcupine”, which has minimal saturation with the seme of death.
We will have to introduce the concept of volume coefficient C(i), as well as the concept of length coefficient CL(L).
However, we cannot dismiss another explanation: when the subject of action remains undefined, consciousness tends to identify it, by default as it were, with the personality of the perceiver (or even more broadly – with the perceiver's world). Thus, the “table of death” is perceived as “Table of your death” or, more broadly still, “Table of death of the world”. Which of these two explanatory attempts comes closer to truth can be demonstrated only through computer-based experimental modeling of the word combination that takes into account the coefficient of word volume.
The development of volume coefficients is, in principle, feasible since the concept of “word volume in text” closely correlates with the traditional theory of sentence parts. This area of linguistics appears to have been researched in sufficient detail to solve our task. In any case, the formula now takes this form:
where the problem of measuring the values of coefficients C and CL remains an open one.
4. The next problem we must solve to determine the boundaries of seme repetition (or, equivalently, text saturation with a given seme) and achieve effective realization of the suggestion formula concerns the role of associations. All associations arising in the perceiver’s mind must form semantic series whose identifiers maintain either repetition symmetry or inversion symmetry with the identifier of the poem's leading semantic series. Accounting for all possible associations a perceiver might form proves extremely difficult. Moreover, associative images can disrupt the rhythm and destroy the suggestion formula.
5. A fundamental question arises: does resonance occur invariably? In other words, will readers always perceive the work as its author does? The answer is no. Mere repetition cannot generate resonance; for resonance to emerge, the total quantity of suggested seme must be distributed throughout the work's space according to some harmonic law – gradually increasing to a local maximum, then falling to the locally maximum value of the inversely symmetric seme, then increasing again, and so on. This growth can occur in two ways, as illustrated in Fig. 1.
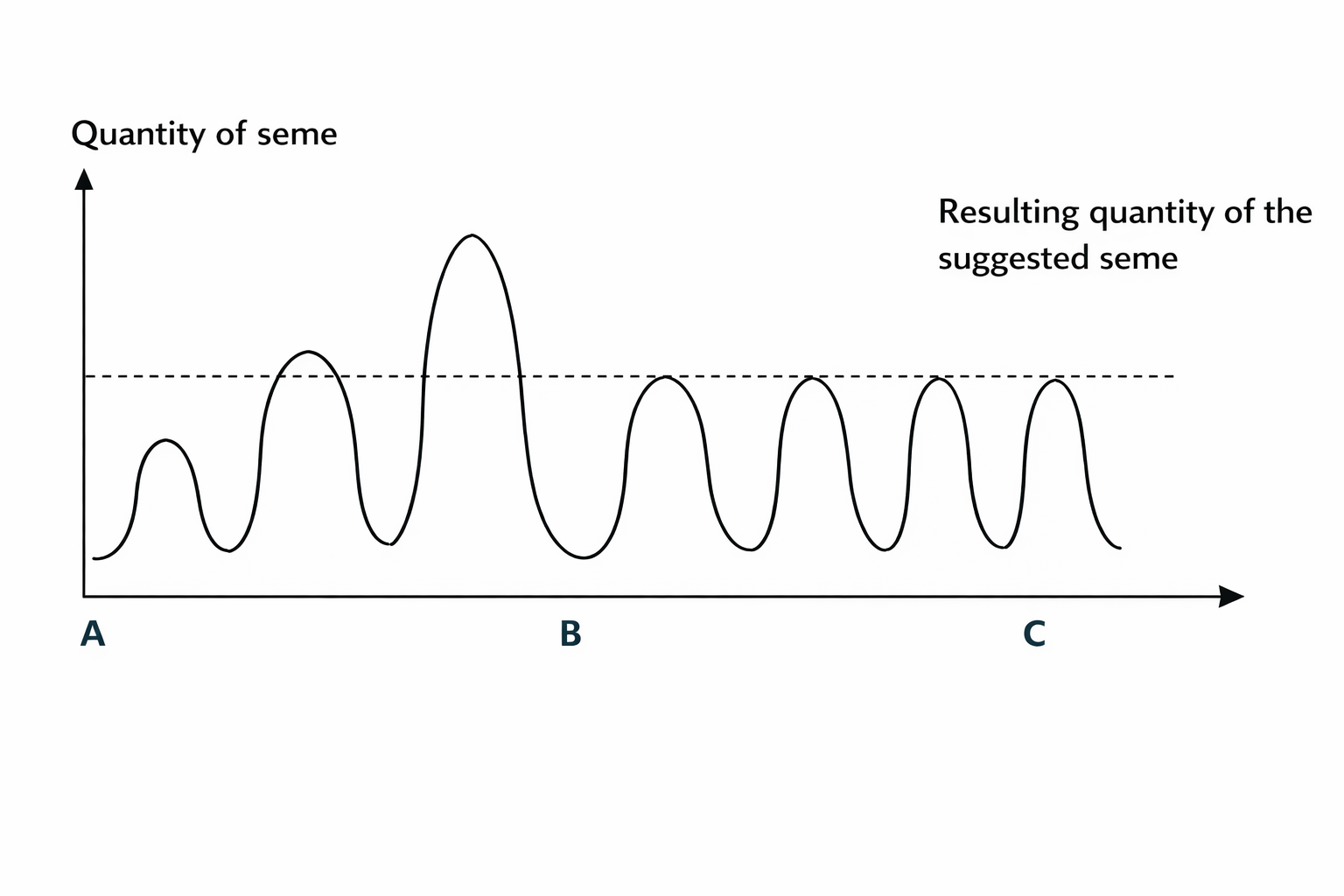
Figure 1. Distribution of seme in text space
Segments AB and BC correspond to two parts of text of equal length. Along segment AB we observe oscillation in seme quantity within words with gradual increase, where the number of seme repetitions per unit length remains constant. Along segment BC – the seme quantity per word remains constant while the number of repetitions per unit length of text increases. The figure thus illustrates the well-known physical principles of amplitude and frequency modulation.
Thus, the proper distribution of seme in text space induces a gradual oscillation of consciousness; this gradualness allows the process to accumulate momentum imperceptibly and, through inertia, increases the probability of selecting the required meaning from each word's semantic field. Meter maintains the proper rhythm of semantic oscillations. Otherwise, an ill-timed or quantitatively inappropriate portion of seme would inhibit the induced process of suggestion (perception) or even destroy proper realization of the suggestion formula. For a work of art to achieve its effect, it must contain an optimal quantity of optimally oscillating leading seme.
As a consequence of these considerations regarding the perception process, we arrive at the following requirement: proper realization of the suggestion formula demands the presence of inversely symmetric elements. Consequently, works where “better” “conflicts” with “good” are inevitably destined to fail. This requirement simply manifests the well-known dialectical law of unity and the struggle of opposites in this sphere of human activity.
6. Another factor influencing the realization of the suggestion formula, which we have not yet considered, is the following: words belonging to one semantic series can, when combined in a phrase, produce an image that does not belong to this series. Consider this example of verbal alchemy from Andrei Bely's poem (1903):
In a crown of fire under the realm of boredom
Above time ascended
Frozen magician, folding hands,
Prophet of timeless spring.
The semantic series present are: 1) crown, fire, realm, time, ascension, prophet, spring; 2) frozen magician, folding hands (yoga pose), boredom, and timelessness.
The identifiers of these series are ascension and immobility. Of particular interest is the line “Above time ascended”. This line is unique: both “above time” and “ascended” belong to the series of ascension, yet their combination creates a sensation of profound immobility.
Bely frequently employed paradoxes of such kind. In this case, the resulting image stands in inverse symmetry to its constituent words. We have seen that inverse symmetry can produce various unexpected effects. However, we cannot simply attribute this discovered phenomenon to inverse symmetry and its paradoxes. We lack sufficient evidence to conclude that words cannot combine to form an image lacking symmetrical relations with existing images in the verse.
We have examined several conditions necessary for the effective realization of the suggestion formula. Undoubtedly, many more such conditions exist – potentially as significant as those we have identified in this chapter. All these conditions are processed instantaneously by some evaluative mechanism that enables us to assess and select appropriate words for any given line. When poets reject certain words, they do so because these words would destroy the formula of the verse being created – either because such words are saturated with the needed seme to a degree greater or lesser than required to fill the lacuna in the text's seme saturation.
This evaluative mechanism functions with varying degrees of effectiveness in different individuals. When we declare one poet more talented than another, we are essentially acknowledging that their word-selection mechanism operates with greater precision. Hence – the superior quality of their verses. This mechanism can be refined – which explains why poets can “grow”. Various factors affect the evaluative mechanism's operation, causing it to function differently at different times – thus we sometimes note that even accomplished poets temporarily lose their feeling for words.
DIGRESSION 1
Earlier we discussed how the suggestion formula can achieve ideal realization. If we accept the possibility of realizing the suggestion formula perfectly in a literary work, then any attempt to interpret such a work in another medium – theater, for instance – must fail. Any change in text saturation with seme (which is inevitable, as actors employ gestures, voice modulations, and other theatrical devices to influence viewers) will diminish the quality of the formula's realization. While theatrical interpretation might enhance the impact of a text with an imperfect suggestion formula, a text with ideal realization cannot be successfully transferred to stage. Is this perhaps why no staging of “Hamlet” has ever exhausted Shakespeare's text? Should we then abandon attempts at equivalent theatrical interpretation of dramatic masterpieces? No – for there is a subtle insight that the creators of Noh theater understood.
Noh plays represent masterpieces of Japanese literature. Their actors deliver text in monotonous, expressionless voices, swallowing syllables, effectively “killing” the text. Instead, they emphasize movement and dance, song and music. The actors wear masks that eliminate facial expression, yet each mask is saturated with its own seme. Thus, Noh theater actors achieve a powerful realization of the suggestion formula by different means. Having weakened suggestion in one aspect, they strengthen it through purely theatrical techniques. In our model, this represents the director's function – to identify optimal paths to realize the suggestion formula. (Indeed, the hypnotic, suggestive aspect of theatrical action in Noh theater is particularly pronounced, further enhanced by the Buddhist themes of Noh plays.)
DIGRESSION 2
If we determine the optimal saturation with seme of a text whose length is L, establish the volume coefficient C(i) for each word, and determine each word’s saturation with the same seme, can we construct an algorithm for machine versification?
In first approximation, perhaps yes. However, we cannot be confident in the quality of machine-generated output, since failure to satisfy even just conditions 4 and 6 (concerning side associations and secondary seme saturation in images created by word combinations) could easily invalidate our already crude formula. These factors appear to be almost unpredictable. Moreover, we must remember that our six conditions for realizing the suggestion formula surely do not exhaust all criteria actually relevant to works of art.
At present, we can assert with certainty only this: solving the problem of machine versification appears impossible without developing a specialized dictionary containing information about all semes in each word's meaning field and that word's saturation levels for each seme. Creating such a dictionary presents an enormously labor-intensive task, with uncertain feasibility. This stems from two factors: first, such a dictionary would become obsolete more rapidly than conventional explanatory dictionaries; second, and more fundamentally, any dictionary treats semes as discrete units, while in reality – a word's semantic meaning field is inherently continuous. How one might identify all semes within a word's meaning field remains unclear.[35]
In concluding this chapter, we must emphasize that nearly all questions raised here require dedicated investigation beyond our present scope. Examining these problems may prove valuable, particularly for machine versification and machine translation. Several concepts outlined in this chapter might benefit cyberneticists working in these areas. At minimum, we can now see how to teach computers to write (admittedly poor) poems using the suggestion formula. Employing the principle of semantic series (composing poems from words in symmetric semantic series) should resolve the primary challenge in mechanizing versification – the problem of combinability. All words within a semantic series naturally combine, each containing the common seme from the outset.[36]